JSON和序列化
很难想象移动应用程序不需要与Web服务器通信或在某个时刻存储结构化数据。 在编写需要联网的应用程序时,我们很可能迟早需要使用JSON。
在本教程中,我们将探讨如何在Flutter中使用JSON。我们回顾一下在不同情况下使用的JSON解决方案以及原因。
哪种JSON序列化方法适合我?
本文介绍了使用JSON的两个常规策略:
- 手动序列化和反序列化
- 通过代码生成自动序列化和反序列化
不同的项目具有不同的复杂度和场景。对于较小项目,使用代码生成器可能会过度。对于具有多个JSON model的复杂应用程序,手动序列化可能会比较重复,并会很容易出错。
小项目手动序列化
手动JSON序列化是指使使用dart:convert中内置的JSON解码器。它将原始JSON字符串传递给JSON.decode() 方法,然后在返回的Map<String, dynamic>中查找所需的值。
它没有外部依赖或其它的设置,对于小项目很方便。
当您的项目变大时,手动编写序列化逻辑可能变得难以管理且容易出错。如果您在访问未提供的JSON字段时输入了一个错误的字段,则您的代码将会在运行时会引发错误。
如果您的项目中JSON model并不多,并且希望快速测试一下,那么手动序列化可能会很方便。有关手动序列化的示例,请参考这里。
在大中型项目中使用代码生成
代码生成功能的JSON序列化是指通过外部库为您自动生成序列化模板。它需要一些初始设置,并运行一个文件观察器,从您的model类生成代码。 例如,json_serializable和built_value就是这样的库。
这种方法适用于较大的项目。不需要手写,如果访问JSON字段时拼写错误,这会在编译时捕获的。代码生成的不利之处在于它涉及到一些初始设置。另外,生成的源文件可能会在项目导航器会显得混乱。
当您有一个中型或大型项目时,您可能想要使用代码生成JSON序列化。要查看基于代码生成JSON序列化的示例,请参见这里。
Flutter中是否有GSON / Jackson / Moshi?
简单的回答是没有.
这样的库需要使用运行时反射,这在Flutter中是禁用的。运行时反射会干扰Dart的_tree shaking_。使用_tree shaking_,我们可以在发版时“去除”未使用的代码。这可以显着优化应用程序的大小。
由于反射会默认使用所有代码,因此_tree shaking_会很难工作。这些工具无法知道哪些widget在运行时未被使用,因此冗余代码很难剥离。使用反射时,应用尺寸无法轻松的进行优化。
虽然我们不能在Flutter中使用运行时反射,但有些库为我们提供了类似易于使用的API,但它们是基于代码生成的。这种方法在代码生成库部分有更详细的介绍。
使用 dart:convert手动序列化JSON
Flutter中基本的JSON序列化非常简单。Flutter有一个内置dart:convert库,其中包含一个简单的JSON编码器和解码器。
以下是一个简单的user model的示例JSON。
{
"name": "John Smith",
"email": "john@example.com"
}
有了dart:convert,我们可以用两种方式来序列化这个JSON model。我们来看看这两种方法:
内连序列化JSON
通过查看dart:转换JSON文档,我们发现可以通过调用JSON.decode方法来解码JSON ,使用JSON字符串作为参数。
Map<String, dynamic> user = JSON.decode(json);
print('Howdy, ${user['name']}!');
print('We sent the verification link to ${user['email']}.');
不幸的是,JSON.decode()仅返回一个Map<String, dynamic>,这意味着我们直到运行时才知道值的类型。
通过这种方法,我们失去了大部分静态类型语言特性:类型安全、自动补全和最重要的编译时异常。这样一来,我们的代码可能会变得非常容易出错。
例如,当我们访问name或email字段时,我们输入的很快,导致字段名打错了。但由于这个JSON在map结构中,所以编译器不知道这个错误的字段名(译者语:所以编译时不会报错)。
在模型类中序列化JSON
我们可以通过引入一个简单的模型类(model class)来解决前面提到的问题,我们称之为User。在User类内部,我们有:
- 一个
User.fromJson构造函数, 用于从一个map构造出一个User实例 map structure - 一个
toJson方法, 将User实例转化为一个map.
这样,调用代码现在可以具有类型安全、自动补全字段(name和email)以及编译时异常。如果我们将拼写错误或字段视为int类型而不是String,
那么我们的应用程序就不会通过编译,而不是在运行时崩溃。
user.dart
class User {
final String name;
final String email;
User(this.name, this.email);
User.fromJson(Map<String, dynamic> json)
: name = json['name'],
email = json['email'];
Map<String, dynamic> toJson() =>
{
'name': name,
'email': email,
};
}
现在,序列化逻辑移到了模型本身内部。采用这种新方法,我们可以非常容易地反序列化user。
Map userMap = JSON.decode(json);
var user = new User.fromJson(userMap);
print('Howdy, ${user.name}!');
print('We sent the verification link to ${user.email}.');
要序列化一个user,我们只是将该User对象传递给该JSON.encode方法。我们不需要手动调用toJson这个方法,因为JSON.encode已经为我们做了。
String json = JSON.encode(user);
这样,调用代码就不用担心JSON序列化了。但是,model类还是必须的。在生产应用程序中,我们希望确保序列化正常工作。在实践中,User.fromJson和User.toJson方法都需要单元测试到位,以验证正确的行为。
另外,实际场景中,JSON对象很少会这么简单,嵌套的JSON对象并不罕见。
如果有什么能为我们自动处理JSON序列化,那将会非常好。幸运的是,有!
使用代码生成库序列化JSON
尽管还有其他库可用,但在本教程中,我们使用了json_serializable package包。 它是一个自动化的源代码生成器,可以为我们生成JSON序列化模板。
由于序列化代码不再由我们手写和维护,我们将运行时产生JSON序列化异常的风险降至最低。
在项目中设置json_serializable
要包含json_serializable到我们的项目中,我们需要一个常规和两个开发依赖项。简而言之,开发依赖项是不包含在我们的应用程序源代码中的依赖项。
通过此链接可以查看这些所需依赖项的最新版本 。
pubspec.yaml
dependencies:
# Your other regular dependencies here
json_annotation: ^2.0.0
dev_dependencies:
# Your other dev_dependencies here
build_runner: ^1.0.0
json_serializable: ^2.0.0
在您的项目根文件夹中运行 flutter packages get (或者在编辑器中点击 “Packages
Get”) 以在项目中使用这些新的依赖项.
以json_serializable的方式创建model类
让我们看看如何将我们的User类转换为一个json_serializable。为了简单起见,我们使用前面示例中的简化JSON model。
user.dart
import 'package:json_annotation/json_annotation.dart';
// user.g.dart 将在我们运行生成命令后自动生成
part 'user.g.dart';
///这个标注是告诉生成器,这个类是需要生成Model类的
@JsonSerializable()
class User{
User(this.name, this.email);
String name;
String email;
//不同的类使用不同的mixin即可
factory User.fromJson(Map<String, dynamic> json) => _$UserFromJson(json);
Map<String, dynamic> toJson() => _$UserToJson(this);
}有了这个设置,源码生成器将生成用于序列化name和email字段的JSON代码。
如果需要,自定义命名策略也很容易。例如,如果我们正在使用的API返回带有_snake_case_的对象,但我们想在我们的模型中使用_lowerCamelCase_, 那么我们可以使用@JsonKey标注:
/// Tell json_serializable that "registration_date_millis" should be
/// mapped to this property.
@JsonKey(name: 'registration_date_millis')
final int registrationDateMillis;
运行代码生成程序
json_serializable第一次创建类时,您会看到与下图类似的错误。
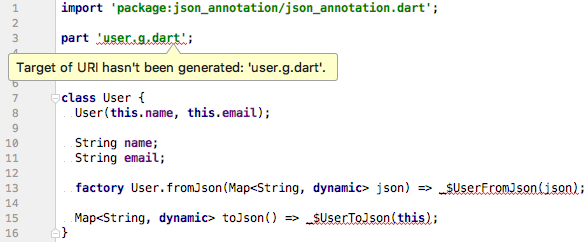
这些错误是完全正常的,这是因为model类的生成代码还不存在。为了解决这个问题,我们必须运行代码生成器来为我们生成序列化模板。
There are two ways of running the code generator. 有两种运行代码生成器的方法:
一次性生成
通过在我们的项目根目录下运行flutter packages pub run build_runner build,我们可以在需要时为我们的model生成json序列化代码。
这触发了一次性构建,它通过我们的源文件,挑选相关的并为它们生成必要的序列化代码。
虽然这非常方便,但如果我们不需要每次在model类中进行更改时都要手动运行构建命令的话会更好。
持续生成
使用_watcher_可以使我们的源代码生成的过程更加方便。它会监视我们项目中文件的变化,并在需要时自动构建必要的文件。我们可以通过flutter packages pub run
build_runner watch在项目根目录下运行来启动_watcher_。
只需启动一次观察器,然后并让它在后台运行,这是安全的。
使用json_serializable模型
要通过json_serializable方式反序列化JSON字符串,我们不需要对先前的代码进行任何更改。
Map userMap = JSON.decode(json);
var user = new User.fromJson(userMap);
序列化也一样。调用API与之前相同。
String json = JSON.encode(user);
有了json_serializable,我们可以在User类上忘记任何手动的JSON序列化 。源代码生成器创建一个名为user.g.dart的文件,它具有所有必需的序列化逻辑。
现在,我们不必编写自动化测试来确保序列化的正常工作 - 这个库会确保序列化工作正常。